What started as a simple Mini PCI Express WiFi card swap on a ThinkPad T61 notebook, turned into deploying a custom BIOS in order to get the card to work. I love ThinkPad notebooks, they are workhorses that keep on going and going. I always keep my older models around for testing, and one ofContinue reading “Circumventing ThinkPad’s WiFi Card Whitelisting”
Category Archives: problem
UPS Battery Replacement Turns Into Unrecoverable Firmware Update
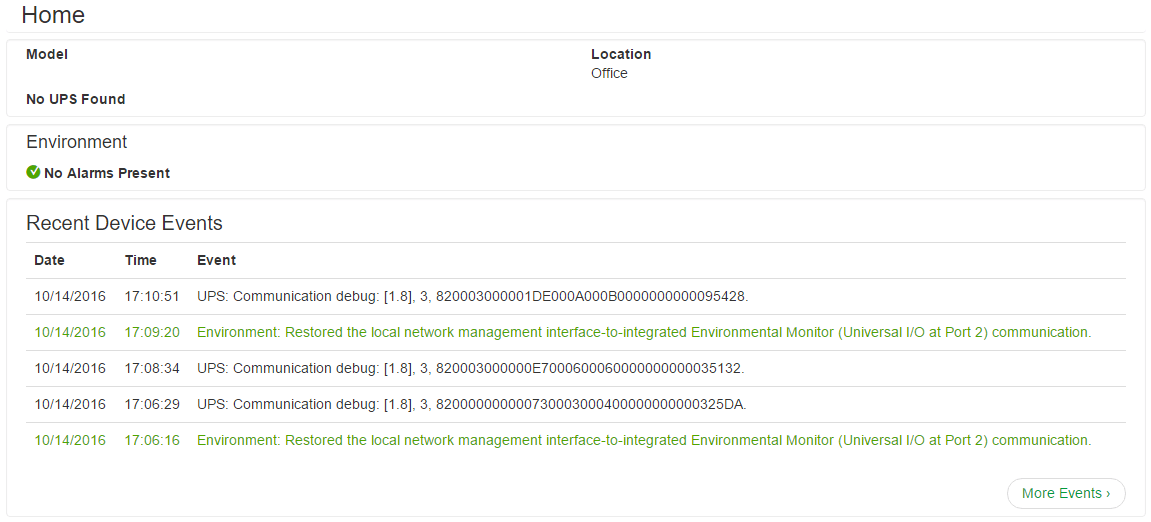
Two lessons learned; do not trust scheduled battery tests, and leave working firmware be!
Amazon Associate’s Account Closed
Amazon just notified me in email that my Associate’s account was closed due to not being in compliance with their operating agreement: “You are not in compliance with Participation Requirement Number 29 because purchases resulting from Special Links on your site have been used for resale or commercial use.” I have no idea how orContinue reading “Amazon Associate’s Account Closed”
Nest Protect False Alarms

2AM, beep, smoke alarm low battery warning, and when one beeps, all the interconnected ones beep, now it is impossible to find which one has a low battery. As for how smoke alarms look, I’ve always wondered who made those terrible aesthetic design choices, maybe it is some kind of industry insider competition to see who can design the ugliestContinue reading “Nest Protect False Alarms”
Electrical Power Quality
Earlier this year we moved a couple miles from Redondo Beach to Manhattan Beach, bigger house, better school district. As far as the house and area is concerned, it is definitely an upgrade, but not so for the utilities. Monthly utilities are a lot more expensive, not so much the per unit fees, but theContinue reading “Electrical Power Quality”
LSI turns their back on Green
I previously blogged here and here on my research into finding a power saving RAID controllers. I have been using LSI MegaRAID SAS 9280-4i4e controllers in my Windows 7 workstations and LSI MegaRAID SAS 9280-8e controllers Windows Server 2008 R2 servers. These controllers work great, my workstations go to sleep and wake up, and inContinue reading “LSI turns their back on Green”
RIP Boxee Box
After nearly six months of no software updates for the Boxee Box, Boxee announced the Boxee TV, and, as far as I’m concerned, the death of the Boxee Box. Boxee is releasing an updated hardware platform, but they are abandoning all local media playback and cataloging capabilities, and instead focusing on a, US only, cloudContinue reading “RIP Boxee Box”
Dyslexic Intel RSTe Driver
I encounter one problem after another running Windows 8 and Server 2012 on the dual Xeon E5 Intel C600 chipset based SuperMicro 7047A-T and 7047A-73 SuperWorkstation machines. I will say that this is really not representative of my Windows 8 experience in general, as all other machines I installed on worked fine with the in-boxContinue reading “Dyslexic Intel RSTe Driver”
Windows 8 VIDEO_TDR_FAILURE Madness
I finally figured out why I kept on getting VIDEO_TDR_FAILURE BSOD’s when installing Windows 8 on my SuperMicro workstations. It turns out that the problem goes away when I use a PCIe slot associated with CPU #1, instead of a slot associated with CPU #2. Some history on my adventures with Windows 8 and SuperMicroContinue reading “Windows 8 VIDEO_TDR_FAILURE Madness”
WordPress.com 404 With Blogger Permalinks
Part of the research I did before migrating from Blogger to WordPress.com, was to make sure that current Blogger permalinks will resolve correctly once the old posts were imported into WordPress.com. At the time all seemed fine, but soon after migrating, I received alerts from Google Webmaster Tools that there is an increase in siteContinue reading “WordPress.com 404 With Blogger Permalinks”

You must be logged in to post a comment.