
I replaced my aging UniFi Security Gateway Pro and slow Circle Home Plus with a Firewalla Gold Plus, giving me gigabit speed firewall and parental controls in a single easy to use and actively developed device. Why Firewalla? We have 1Gbps internet, and I want a feature rich firewall that can operate at line speed.Continue reading “Moving from UniFi-USG and Circle to Firewalla”
Category Archives: performance
Unraid User-Share vs. Disk-Share SMB Performance
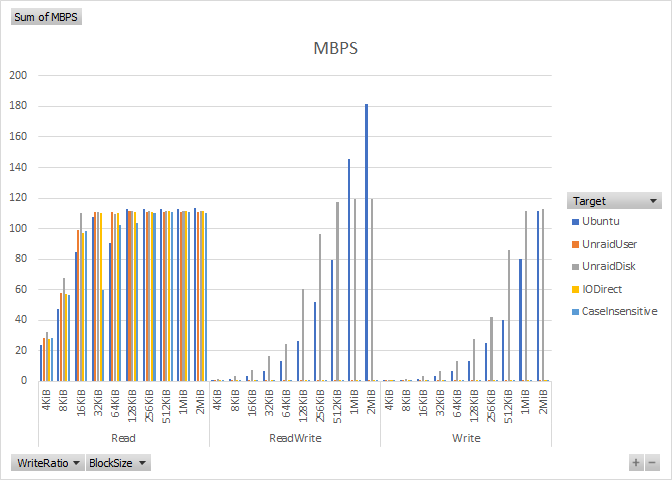
This is yet another post on Unraid’s poor SMB performance, but I think I narrowed down the cause of the problem to the Unraid FUSE filesystem. I discovered this about 2 months ago, but with COVID-19 and no kids weekend sporting event duties, I have some time to post. In this round of testing IContinue reading “Unraid User-Share vs. Disk-Share SMB Performance”
Unraid vs. Ubuntu Bare Metal SMB Performance

In my last test I compared Unraid SMB performance with an Ubuntu VM running on Unraid, and Ubuntu outperformed Unraid. I was wondering if the VM disk image synthetically improved performance, maybe IO caching, so this time I tested Ubuntu on the same hardware that runs Unraid. I configured the system to boot from eitherContinue reading “Unraid vs. Ubuntu Bare Metal SMB Performance”
Unraid vs. Ubuntu SMB Performance
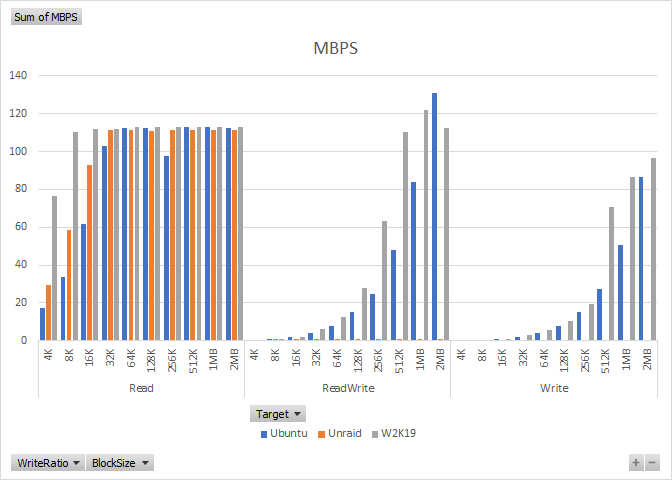
In my last round of testing I found that Unraid v6.8 SMB still underperforms compared to Windows Server 2019, but I was wondering if it is a Linux Samba problem, or an Unraid problem. I installed an Ubuntu Server 18.04.3 LTS VM on Unraid, bridged network, 16GB RAM, 128GB raw disk located on the BTRSContinue reading “Unraid vs. Ubuntu SMB Performance”
Unraid SMB Performance: v6.7.2 vs. v6.8.1
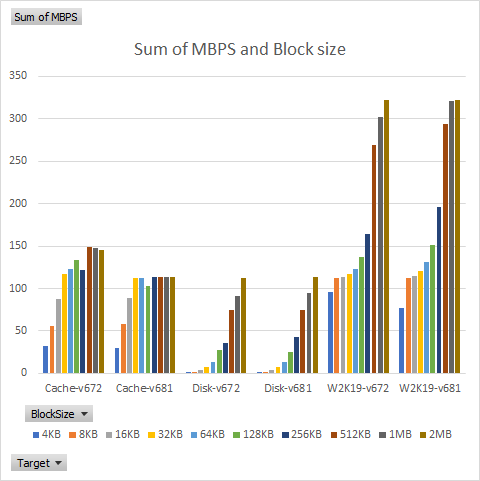
I previously wrote about the poor SMB performance I experienced in Unraid v6.7.2. Unraid v6.8 supposedly addressed SMB performance issues for concurrent read and write operations, and after waiting for the first bugfix release of v6.8, I re-tested using v6.8.1. In my last test I used a combination of batch files and copy and paste,Continue reading “Unraid SMB Performance: v6.7.2 vs. v6.8.1”
Unraid in production, a bit rough around the edges, and terrible SMB performance
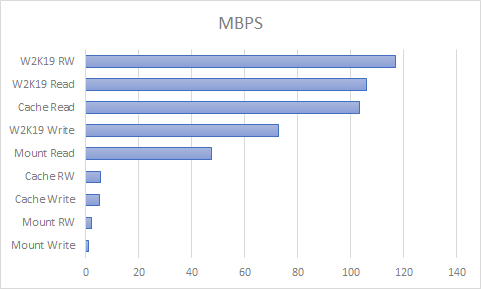
In my last two posts I described how I migrated from W2K16 and hardware RAID6 to Unraid. Now that I’ve had two Unraid servers in production for a while, I’ll describe some of the good and not so good I experienced. Running Docker on Unraid is magnitudes easier compared to getting Docker to work on Windows. DockerContinue reading “Unraid in production, a bit rough around the edges, and terrible SMB performance”
Synology DS2411+ Performance Review
In my last post I compared the performance of Synology DS1511+ against the QNAP TS-859 Pro. As I finished writing that post, Synology announced the new Synology DS2411+. Instead of using a DS1511+ and DX510 extender for 10 disks, the DS2411+ offers 12 disks in a single device. The price difference is also marginal, DS1511+Continue reading “Synology DS2411+ Performance Review”
Synology DS1511+ vs. QNap TS-859 Pro, iSCSI MPIO Performance
Untitled Page I have been very happy with my QNap TS-859 Pro (Amazon), but I’ve run out of space while archiving my media collection, and I needed to expand the storage capacity. You can read about my experience with the TS-859 Pro here, and my experience archiving my media collection here. My primary objective withContinue reading “Synology DS1511+ vs. QNap TS-859 Pro, iSCSI MPIO Performance”

You must be logged in to post a comment.