I finally took the plunge and moved from from Unraid to Proxmox VE. I used to love Unraid, but at some point the easy to use web management UI and app store ecosystem simply lacked capabilities I needed for deployment automation and configuration tasks. Then there is the problem with the poor IO performance, thatContinue reading “Moving from Unraid to Proxmox VE”
Tag Archives: unraid
Unraid User-Share vs. Disk-Share SMB Performance
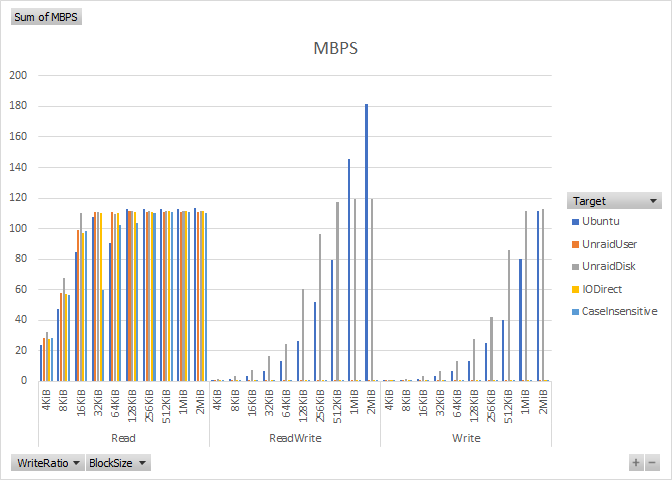
This is yet another post on Unraid’s poor SMB performance, but I think I narrowed down the cause of the problem to the Unraid FUSE filesystem. I discovered this about 2 months ago, but with COVID-19 and no kids weekend sporting event duties, I have some time to post. In this round of testing IContinue reading “Unraid User-Share vs. Disk-Share SMB Performance”
Unraid vs. Ubuntu Bare Metal SMB Performance

In my last test I compared Unraid SMB performance with an Ubuntu VM running on Unraid, and Ubuntu outperformed Unraid. I was wondering if the VM disk image synthetically improved performance, maybe IO caching, so this time I tested Ubuntu on the same hardware that runs Unraid. I configured the system to boot from eitherContinue reading “Unraid vs. Ubuntu Bare Metal SMB Performance”
Unraid vs. Ubuntu SMB Performance
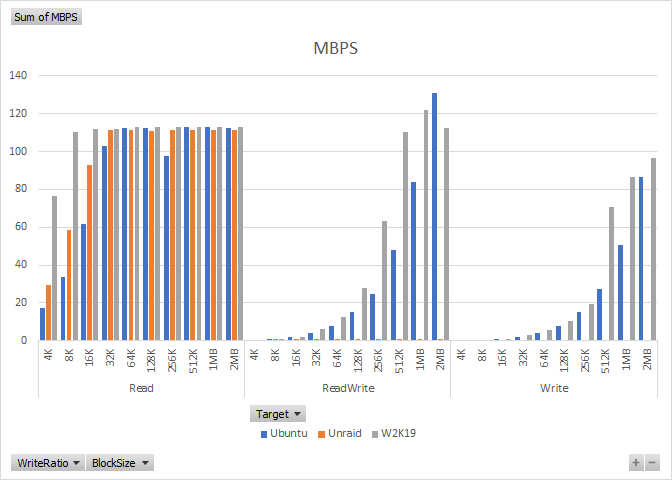
In my last round of testing I found that Unraid v6.8 SMB still underperforms compared to Windows Server 2019, but I was wondering if it is a Linux Samba problem, or an Unraid problem. I installed an Ubuntu Server 18.04.3 LTS VM on Unraid, bridged network, 16GB RAM, 128GB raw disk located on the BTRSContinue reading “Unraid vs. Ubuntu SMB Performance”
Unraid SMB Performance: v6.7.2 vs. v6.8.1
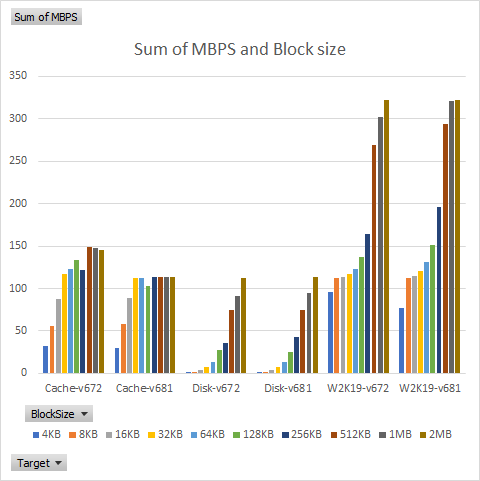
I previously wrote about the poor SMB performance I experienced in Unraid v6.7.2. Unraid v6.8 supposedly addressed SMB performance issues for concurrent read and write operations, and after waiting for the first bugfix release of v6.8, I re-tested using v6.8.1. In my last test I used a combination of batch files and copy and paste,Continue reading “Unraid SMB Performance: v6.7.2 vs. v6.8.1”
Unraid repeat parity errors on reboot

This post started with a quick experiment, but after hardware incompatibilities forced me to swap SSD drives, and subsequently losing a data volume, it turned into a much bigger effort. My two Unraid servers have been running nonstop without any issues for many months, last I looked the uptime on v6.7.2 was around 240 days.Continue reading “Unraid repeat parity errors on reboot”
Unraid in production, a bit rough around the edges, and terrible SMB performance
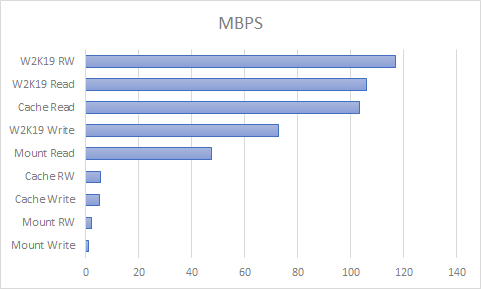
In my last two posts I described how I migrated from W2K16 and hardware RAID6 to Unraid. Now that I’ve had two Unraid servers in production for a while, I’ll describe some of the good and not so good I experienced. Running Docker on Unraid is magnitudes easier compared to getting Docker to work on Windows. DockerContinue reading “Unraid in production, a bit rough around the edges, and terrible SMB performance”
Unraid and Robocopy Problems
In my last post I described how I converted one of my W2K16 servers to Unraid, and how I am preparing for conversion of the second server. As I’ve been copying all my data from W2K16 to Unraid, I discovered some interesting discrepancies between W2K16 SMB and Unraid SMB. I use robocopy to mirror filesContinue reading “Unraid and Robocopy Problems”
Moving from W2K16 to Unraid

I have been happy with my server rack running my UniFi network equipment and two Windows Server 2016 (W2K16) instances. I use the servers for archiving my media collection and running Hyper-V for all sorts of home projects and work related experiments. But, time moves on, one can never have enough storage, and technology changes. SoContinue reading “Moving from W2K16 to Unraid”

You must be logged in to post a comment.