
What started as a small project quickly snowballed; taking way more time than anticipated, going through multiple scrapped plans and hardware changes, my fingers still hurting from making cables and pushing pixels through corrugated plastic. But for all the overkill, it does look pretty. It started when I ordered two strands of Govee RGB patioContinue reading “Getting carried away with RGB holiday lights”
Category Archives: power
ESP32 Water and Gas Utility Meter

The recent release of Home Assistant’s energy dashboard inspired me to restore my gas and water utility meter monitors. I lost the measurements when I removed my Brultech GreenEye energy meters in favor of Sense energy monitors. To recap, my local city and utilities do not allow any connections in any form to their utilityContinue reading “ESP32 Water and Gas Utility Meter”
Abandoning GreenEye for Sense

I planned whole a house energy monitoring setup when we built our house. But in all these years I never completed the Brultech GreenEye installation, I officially called that plan abandoned, and instead installed Sense energy monitors. First a bit of a history, skip to the end if you’re not interested in my procrastination journey.Continue reading “Abandoning GreenEye for Sense”
UPS Battery Replacement Turns Into Unrecoverable Firmware Update
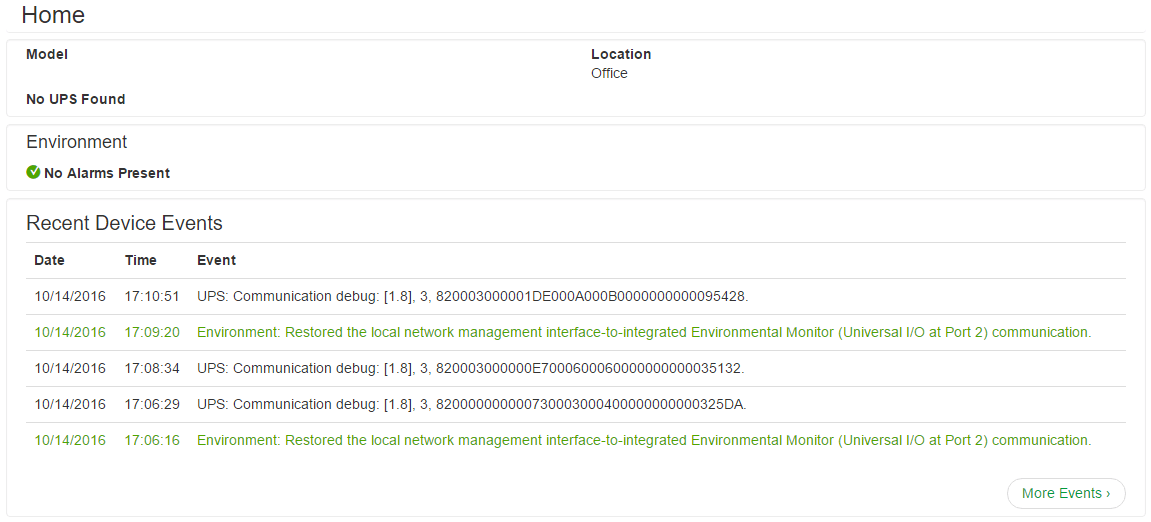
Two lessons learned; do not trust scheduled battery tests, and leave working firmware be!
Electrical Power Quality
Earlier this year we moved a couple miles from Redondo Beach to Manhattan Beach, bigger house, better school district. As far as the house and area is concerned, it is definitely an upgrade, but not so for the utilities. Monthly utilities are a lot more expensive, not so much the per unit fees, but theContinue reading “Electrical Power Quality”
LSI turns their back on Green
I previously blogged here and here on my research into finding a power saving RAID controllers. I have been using LSI MegaRAID SAS 9280-4i4e controllers in my Windows 7 workstations and LSI MegaRAID SAS 9280-8e controllers Windows Server 2008 R2 servers. These controllers work great, my workstations go to sleep and wake up, and inContinue reading “LSI turns their back on Green”
Synology DS2411+ Performance Review
In my last post I compared the performance of Synology DS1511+ against the QNAP TS-859 Pro. As I finished writing that post, Synology announced the new Synology DS2411+. Instead of using a DS1511+ and DX510 extender for 10 disks, the DS2411+ offers 12 disks in a single device. The price difference is also marginal, DS1511+Continue reading “Synology DS2411+ Performance Review”
Power Saving RAID Controller (Continued)
This post continues from my last post on power saving RAID controllers. It turns out the Adaptec 5 series controller are not that workstation friendly. I was testing with Western Digital drives; 1TB Caviar Black WD1001FALS, 2TB Caviar Green WD20EADS, and 1TB RE3 WD1002FBYS. I also wanted to test with the new 2TB RE4-GP WD2002FYPSContinue reading “Power Saving RAID Controller (Continued)”
Power Saving SATA RAID Controller
I’ve been a longtime user of Adaptec SATA RAID cards (3805, 5805, 51245), but over the years I’ve become more energy saving conscious, and the Adaptec controllers did not support Windows power management. My workstations are normally running in the “Balanced” power mode so that they will go to sleep after an hour, but sometimesContinue reading “Power Saving SATA RAID Controller”

You must be logged in to post a comment.