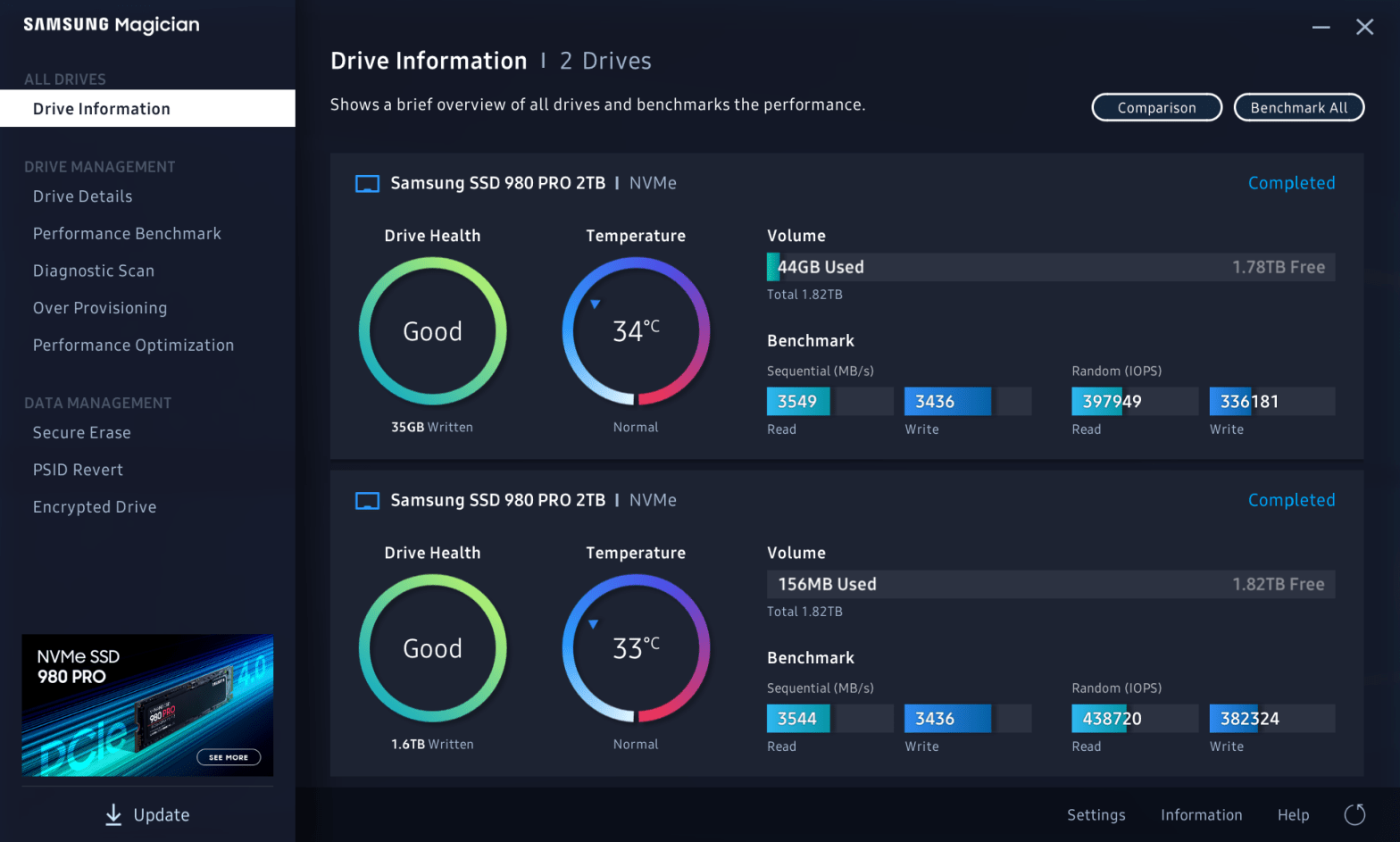
The SSD in my Windows 10 system started reporting failures, and as luck would have it, died while I was cloning it to a new drive. I suspect death was caused by overheating, and I addressed that with my new setup. This Windows 10 system is in a NCase M1 v5 SFF case with anContinue reading “Cooling an Overheating MVMe SSD”
Category Archives: storage
Moving from Unraid to Proxmox VE
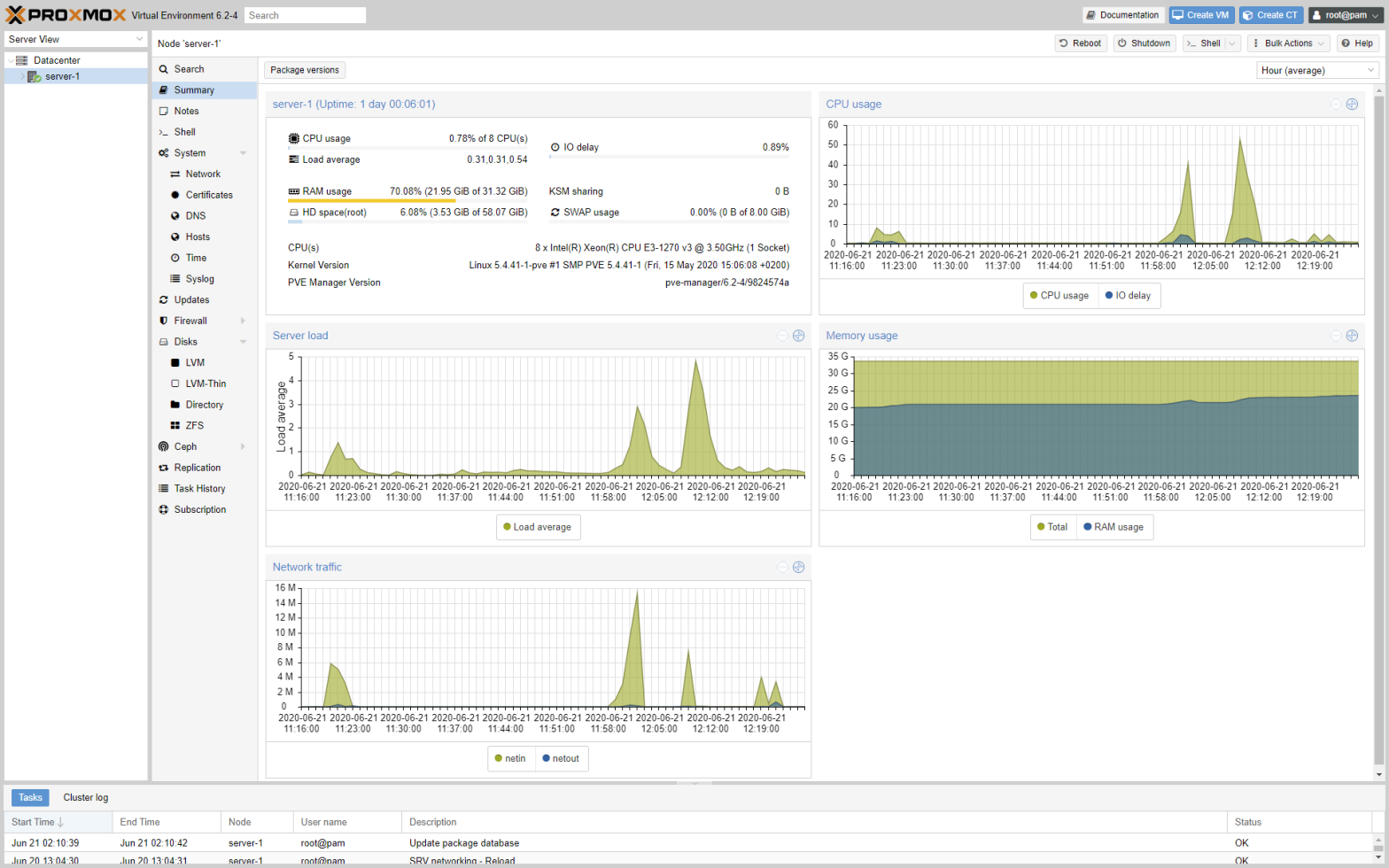
I finally took the plunge and moved from from Unraid to Proxmox VE. I used to love Unraid, but at some point the easy to use web management UI and app store ecosystem simply lacked capabilities I needed for deployment automation and configuration tasks. Then there is the problem with the poor IO performance, thatContinue reading “Moving from Unraid to Proxmox VE”
Recovering the Firmware on a Supermicro BPN-SAS3-846EL1 Backplane

In a previous adventure I replaced an Adaptec HBA with a LSI SAS3 HBA, and the chassis drive bay LED’s stopped working. I suspect the LSI card does not play nice with the SGPIO sideband controller, and I decided to replace the chassis with one similar to my SC846 chassis, where the LSI card andContinue reading “Recovering the Firmware on a Supermicro BPN-SAS3-846EL1 Backplane”
Unraid SMB Performance: v6.7.2 vs. v6.8.1
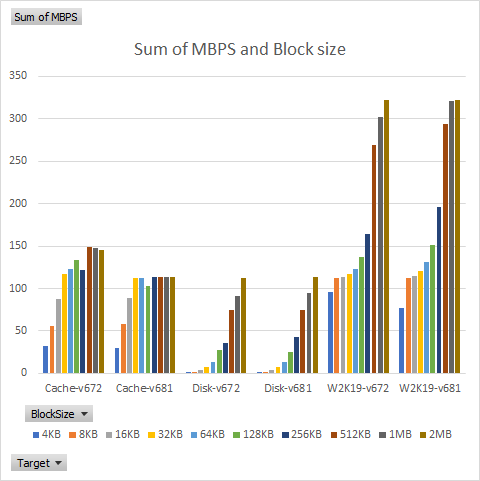
I previously wrote about the poor SMB performance I experienced in Unraid v6.7.2. Unraid v6.8 supposedly addressed SMB performance issues for concurrent read and write operations, and after waiting for the first bugfix release of v6.8, I re-tested using v6.8.1. In my last test I used a combination of batch files and copy and paste,Continue reading “Unraid SMB Performance: v6.7.2 vs. v6.8.1”
Unraid repeat parity errors on reboot

This post started with a quick experiment, but after hardware incompatibilities forced me to swap SSD drives, and subsequently losing a data volume, it turned into a much bigger effort. My two Unraid servers have been running nonstop without any issues for many months, last I looked the uptime on v6.7.2 was around 240 days.Continue reading “Unraid repeat parity errors on reboot”
Unraid and Robocopy Problems
In my last post I described how I converted one of my W2K16 servers to Unraid, and how I am preparing for conversion of the second server. As I’ve been copying all my data from W2K16 to Unraid, I discovered some interesting discrepancies between W2K16 SMB and Unraid SMB. I use robocopy to mirror filesContinue reading “Unraid and Robocopy Problems”
Moving from W2K16 to Unraid

I have been happy with my server rack running my UniFi network equipment and two Windows Server 2016 (W2K16) instances. I use the servers for archiving my media collection and running Hyper-V for all sorts of home projects and work related experiments. But, time moves on, one can never have enough storage, and technology changes. SoContinue reading “Moving from W2K16 to Unraid”
CrashPlan throws in the towel … for home users
Today CrashPlan, my current online backup provider, announced on Facebook of all places, that they threw in the towel, and will no longer provide service to home users. The backlash was heated, and I found the CEO’s video message on the blog post rather condescending. I’ve been a long time user of online backup providers,Continue reading “CrashPlan throws in the towel … for home users”
Rack that server

It’s been a year and a half since we moved into the new house, and I finally have the servers racked in the garage. Looks pretty nice compared to my old setups. My old setup was as follows: Two DELL OptiPlex 990 small form factor machines with Windows Server 2008 R2 as Hyper-V servers. One serverContinue reading “Rack that server”
LSI turns their back on Green
I previously blogged here and here on my research into finding a power saving RAID controllers. I have been using LSI MegaRAID SAS 9280-4i4e controllers in my Windows 7 workstations and LSI MegaRAID SAS 9280-8e controllers Windows Server 2008 R2 servers. These controllers work great, my workstations go to sleep and wake up, and inContinue reading “LSI turns their back on Green”

You must be logged in to post a comment.