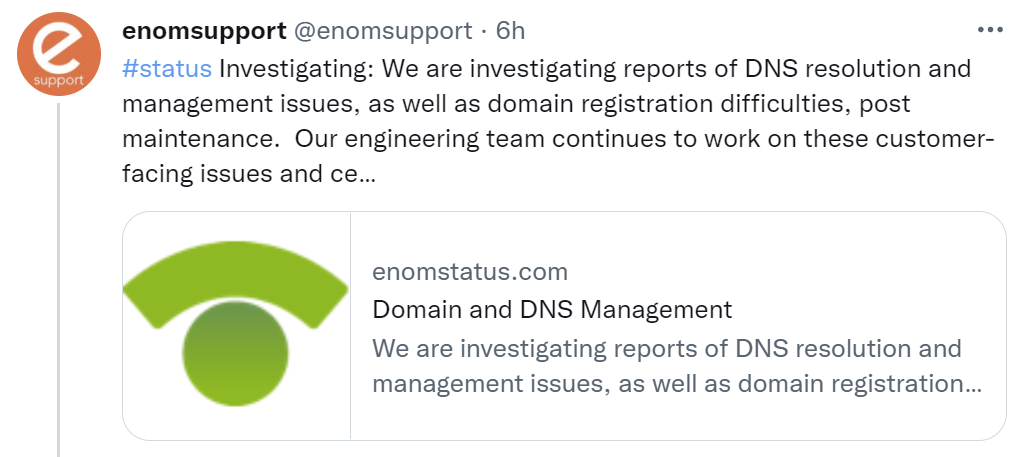
eNom really borked their datacenter move resulting in two days and counting of no DNS. I first noticed the issue Saturday (15 Jan 2022) night when my inbox remained clean for several hours, yes, I am one of those people that like to keep email organized and the inbox clean. A bit of head scratchingContinue reading “eNom Datacenter Move Borks DNS”
Category Archives: problem
Using ESP to Debug an ESP
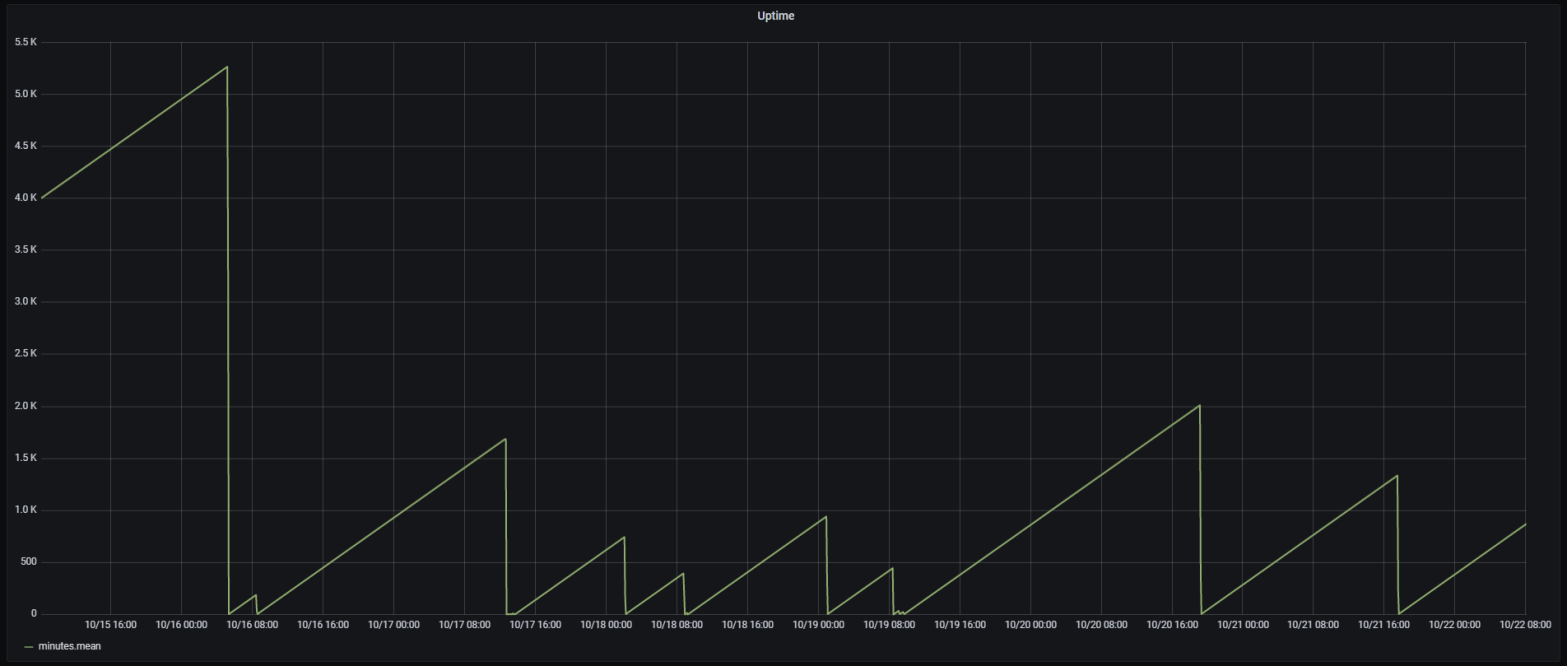
This post is about troubleshooting the sporadic ESP8266 hardware watchdog resets in my water recirculation pump controller project. The ESP8266 would randomly restart, which I can observe by monitoring the uptime reported by ESPHome to Home Assistant. It is difficult to debug because the Sonoff TH10 is in a waterproof case in my garage, makingContinue reading “Using ESP to Debug an ESP”
Unraid vs. Ubuntu Bare Metal SMB Performance

In my last test I compared Unraid SMB performance with an Ubuntu VM running on Unraid, and Ubuntu outperformed Unraid. I was wondering if the VM disk image synthetically improved performance, maybe IO caching, so this time I tested Ubuntu on the same hardware that runs Unraid. I configured the system to boot from eitherContinue reading “Unraid vs. Ubuntu Bare Metal SMB Performance”
Recovering the Firmware on a Supermicro BPN-SAS3-846EL1 Backplane

In a previous adventure I replaced an Adaptec HBA with a LSI SAS3 HBA, and the chassis drive bay LED’s stopped working. I suspect the LSI card does not play nice with the SGPIO sideband controller, and I decided to replace the chassis with one similar to my SC846 chassis, where the LSI card andContinue reading “Recovering the Firmware on a Supermicro BPN-SAS3-846EL1 Backplane”
Unraid repeat parity errors on reboot

This post started with a quick experiment, but after hardware incompatibilities forced me to swap SSD drives, and subsequently losing a data volume, it turned into a much bigger effort. My two Unraid servers have been running nonstop without any issues for many months, last I looked the uptime on v6.7.2 was around 240 days.Continue reading “Unraid repeat parity errors on reboot”
Unraid in production, a bit rough around the edges, and terrible SMB performance
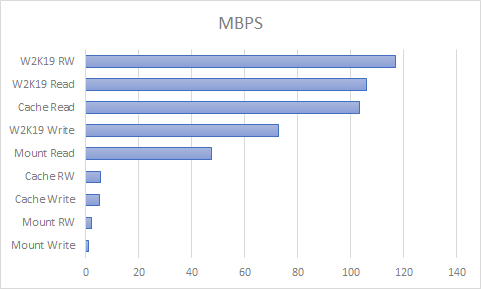
In my last two posts I described how I migrated from W2K16 and hardware RAID6 to Unraid. Now that I’ve had two Unraid servers in production for a while, I’ll describe some of the good and not so good I experienced. Running Docker on Unraid is magnitudes easier compared to getting Docker to work on Windows. DockerContinue reading “Unraid in production, a bit rough around the edges, and terrible SMB performance”
Unraid and Robocopy Problems
In my last post I described how I converted one of my W2K16 servers to Unraid, and how I am preparing for conversion of the second server. As I’ve been copying all my data from W2K16 to Unraid, I discovered some interesting discrepancies between W2K16 SMB and Unraid SMB. I use robocopy to mirror filesContinue reading “Unraid and Robocopy Problems”
eNom Dynamic DNS Update Problems
Update: On 27 July 2018 eNom support notified me by email that the issue is resolved. I tested it, and all is back to normal with DNS-O-Matic. Sometime between 12 May 2018 and 24 May 2018 the eNom dynamic DNS update mechanism stopped working. I use the very convenient DNS-O-Matic dynamic DNS update service toContinue reading “eNom Dynamic DNS Update Problems”
Razer BSOD When Driver Verifier is Enabled
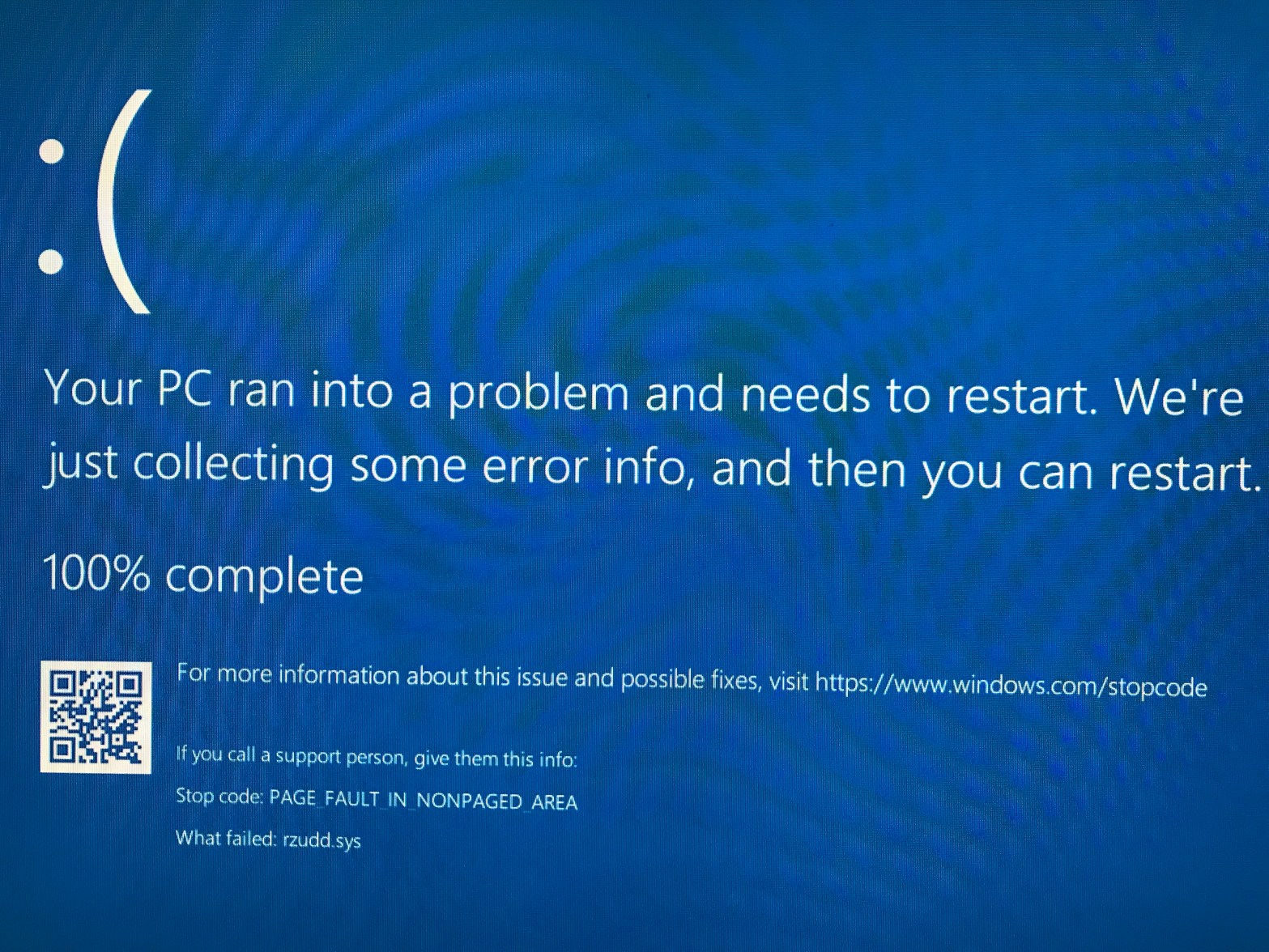
I am done with Razer, exciting promises for technology on paper, great looking hardware, terrible support, terrible software.
Razer Shoddy Support and Bad Software UX
This post is just me venting my frustration at Razer’s poor software user experience, and their shoddy support practices. I’m writing this after I just had to go and find a working mouse, so I could click a button on a dialog that had no keyboard navigation support. I’ve been using Razer keyboards and mice forContinue reading “Razer Shoddy Support and Bad Software UX”

You must be logged in to post a comment.